노션의 Postgres 샤딩을 통한 교훈
위 문서를 번역하였습니다.
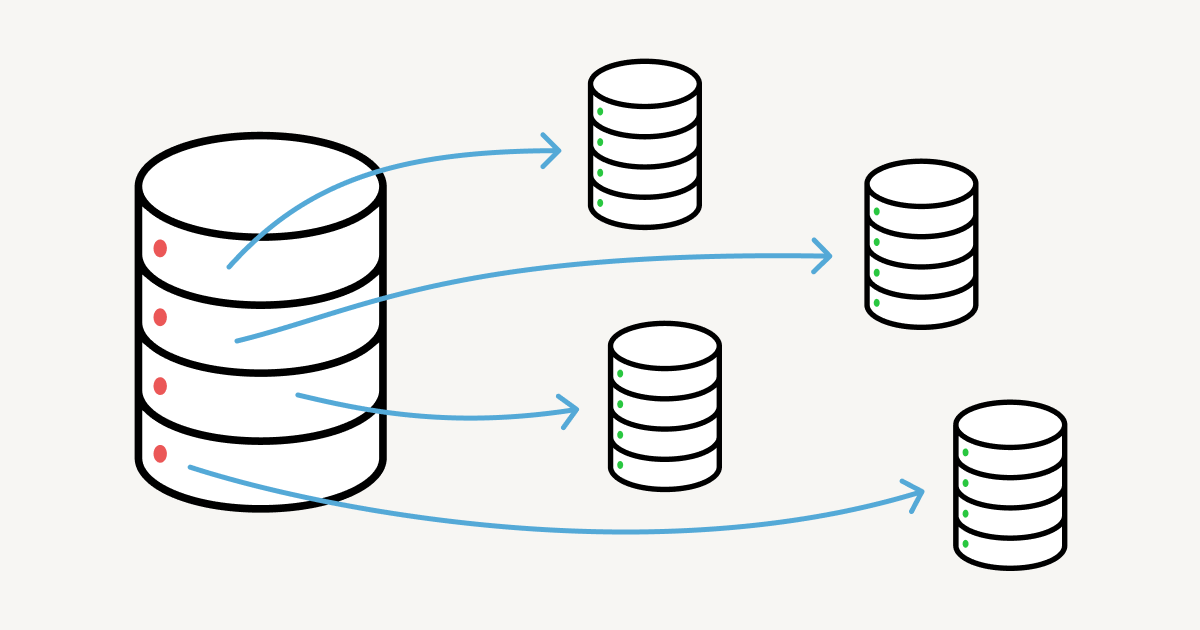
Earlier this year, we took Notion down for five minutes of scheduled maintenance. While our announcement gestured at “increased stability and performance,” behind the scenes was the culmination of months of focused, urgent teamwork: sharding Notion’s PostgreSQL monolith into a horizontally-partitioned database fleet.
올해 초에 노션을 예정된 유지보수를 위해 5분 동안 내렸습니다. 공지는 "증가된 안정성과 성능"을 이야기 했으나, 그 내막에는 몇 달간 빡세게 집중한 긴박한 팀워크가 있었습니다. 이는 노션의 모놀리스 PostgreSQL를 수평 파티션(horizontally-partitioned) 된 데이터베이스 플릿으로 샤딩하는 일이였죠.
The shard nomenclature is thought to originate from the MMORPG Ultima Online, when the game developers needed an in-universe explanation for the existence of multiple game servers running parallel copies of the world. Specifically, each shard emerged from a shattered crystal through which the evil wizard Mondain had previously attempted to seize control of the world.
샤드라는 용어는 MMORPG인 '울티마 온라인'에서 유래되었으며, 게임 개발자들이 병렬로 복사된 세상으로 돌아가는 여러 게임 서버들의 존재를 세계관에 빗대어 설명하기 위해 필요로 했습니다. 구체적으로, 각 샤드는 악당 마법사 몬데인(Mondain)이 이전에 세계를 지배하려고 했을 때 흩뿌려진 크리스탈로부터 나타났습니다.
While the switchover succeeded to much jubilation, we remained quiet in case of any post-migration hiccups. To our delight, users quickly began to notice the improvement:
스위치오버가 큰 기쁨과 함께 성공했지만, 마이그레이션 이후 발생할 수 있는 트러블에 대비하여 조용히 지켜보았습니다. 기쁜점은, 사용자들이 이 개선에 대해 빠르게 알아차리기 시작했다는 점이에요.

But a single maintenance window doesn’t tell the whole story. Our team spent months architecting this migration to make Notion faster and more reliable for years to come.
그러나 하나의 메인터넌스 윈도우로만은 전체 이야기를 다 전달하지는 못합니다. 노션 팀은 여러 해에 걸쳐 노션을 더 빠르고 신뢰성 있는 노션을 만들기 위해 몇 달 동안 이 마이그레이션 작업을 설계했습니다.
Let me tell you the story of how we sharded and what we learned along the way.
이제 어떻게 샤딩을 하고 그 과정에서 어떤 것을 배웠는지 이야기 해드릴게요.
Deciding when to shard
언제 샤딩할 지 결정하기
Sharding represented a major milestone in our ongoing bid to improve application performance. Over the past few years, it’s been gratifying and humbling to see more and more people adopt Notion into every aspect of their lives. And unsurprisingly, all of the new company wikis, project trackers, and Pokédexes have meant billions of new blocks, files, and spaces to store. By mid-2020, it was clear that product usage would surpass the abilities of our trusty Postgres monolith, which had served us dutifully through five years and four orders of magnitude of growth. Engineers on-call often woke up to database CPU spikes, and simple catalog-only migrations became unsafe and uncertain.
샤딩은 애플리케이션 성능을 위한 지속적인 시도 중에서도 주요한 마일스톤이였습니다. 지난 몇 년 동안, 점점 더 많은 사용자들이 그들 삶의 모든 측면에서 노션을 적용하는 것을 보며 흐뭇하고 또 겸손함을 동시에 느꼈습니다. 그리고 놀랍지도 않게도, 새로운 회사의 위키들부터 프로젝트 트래커 그리고 포켓몬 도감까지, 이 것들이 의미하는 것은 저장해야 할 수십억개의 새로운 블록, 파일 그리고 공간을 의미한다는 것이였죠. 2020년 중반에는 제품 사용량이 Postgres 모놀리스를 뛰어넘을 것이 명확해졌습니다. 이 Posgres 모놀리스는 5년간 4개의 시리즈 성장을 겪으며 충실하게 데이터를 제공해주었어요. 온콜 엔지니어들이 종종 CPU 스파이크로 깨어나야 했고, 간단한 카탈로그-온리 마이그레이션이 안전하지 않고 불확실해지게 되었습니다.
When it comes to sharding, fast-growing startups must navigate a delicate tradeoff. During the aughts, an influx of blog posts expounded the perils of sharding prematurely: increased maintenance burden, newfound constraints in application-level code, and architectural path dependence.¹ Of course, at our scale sharding was inevitable. The question was simply when.
샤딩 시기가 오면, 빠르게 성장하는 스타트업들은 섬세한 트레이드 오프를 해야 합니다. 2000년대 초반, 블로그 글들이 조기에 샤딩하는 것의 위험성을 설명해왔습니다. 증가한 유지보수 부담, 응용 프로그램 수준의 코드에서 발생하는 새로운 제약 사항 및 구조적 경로 의존성. 물론, 노션의 규모에서는 샤딩이 불가피했습니다. 단순히 언제인지가 문제였습니다.
For us, the inflection point arrived when the Postgres VACUUM process began to stall consistently, preventing the database from reclaiming disk space from dead tuples. While disk capacity can be increased, more worrying was the prospect of transaction ID (TXID) wraparound, a safety mechanism in which Postgres would stop processing all writes to avoid clobbering existing data. Realizing that TXID wraparound would pose an existential threat to the product, our infrastructure team doubled down and got to work.
노션의 경우, Postgres의 VACUUM 프로세스가 거듭되어 지연되기 시작하고, 죽은 튜플로부터 디스크 공간 회수를 하지 못하게 되면서 변곡점이 찾아오게 됩니다. 디스크 공간은 증가시킬 수 있었지만 더 우려되는 부분은 트랜잭션 ID(TXID) 랩어라운드의 가능성이였습니다. 이는 Postgres의 안전 메커니즘으로, 기존 데이터를 덮어쓰는 것을 막기 위해 모든 쓰기를 중단시킬 수도 있습니다. TXID 랩어라운드가 제품의 근본적인 위협이라는 것을 깨닫고, 인프라 팀은 열심히 작업에 착수했습니다.
Designing a sharding scheme
샤딩 스킴 설계하기
If you’ve never sharded a database before, here’s the idea: instead of vertically scaling a database with progressively heftier instances, horizontally scale by partitioning data across multiple databases. Now you can easily spin up additional hosts to accommodate growth. Unfortunately, now your data is in multiple places, so you need to design a system that maximizes performance and consistency in a distributed setting.
만약 이전에 데이터베이스를 샤딩해본 적이 없다면, 여기에 아이디어가 있습니다. 데이터베이스를 점진적으로 더 무거운 인스턴스로 수직확장하는 대신, 데이터를 여러 데이터베이스에 걸쳐 파티셔닝해서 수평으로 확장하는 방법입니다. 이제 성장을 수용하기 위해 쉽게 추가 호스트를 스핀업 할 수 있습니다. 그러나 불행하게도 여러분의 데이터는 이제 여러 곳에 존재하게 되기 때문에 분산 환경에서 성능과 일관성을 극대화하는 시스템을 설계해야하죠.
Why not just keep scaling vertically? As we found, playing Cookie Clicker with the RDS “Resize Instance” button is not a viable long-term strategy — even if you have the budget for it. Query performance and upkeep processes often begin to degrade well before a table reaches the maximum hardware-bound size; our stalling Postgres auto-vacuum was an example of this soft limitation.
왜 수직으로 확장하는 것을 계속하지 않을까요? 알아낸 바로는, RDS의 "인스턴스 크기 조정" 버튼으로 쿠키 클리커를 하는 것은 실질적으로 지속 가능한 장기 전략이 아닙니다. 예산이 있다 하더라도 말이죠. 쿼리 성능 및 유지 관리 프로세스는 종종 테이블이 최대 하드웨어 한계 크기에 도달하기 훨씬 전에 저하되기 시작합니다. 앞서 이야기 한 지연된 Postgres 자동 VACUUM도 이러한 소프트 리미트의 예시 중 하나였죠.
Application-level sharding
애플리케이션 레벨 샤딩
We decided to implement our own partitioning scheme and route queries from application logic, an approach known as application-level sharding. During our initial research, we also considered packaged sharding/clustering solutions such as Citus for Postgres or Vitess for MySQL. While these solutions appeal in their simplicity and provide cross-shard tooling out of the box, the actual clustering logic is opaque, and we wanted control over the distribution of our data.²
독자적인 파티셔닝 스킴과 애플리케이션 로직에서 쿼리를 라우팅하는 방법을 구현하기로 결정했습니다. 이 접근법은 애플리케이션 레벨 샤딩으로도 알려져있습니다. 초반에 연구 단계에서, Posgres를 위한 Citus나 MySQL를 위한 Vitess 같은 샤딩/클러스터링 솔루션을 고려하기도 했습니다. 이러한 솔루션들은 단순성 측면에서 매력적이며 크로스 샤드간 툴을 제공해주지만, 실제로 클러스터링 로직은 불투명하며 무엇보다 우리는 데이터에 대한 분포를 제어하기를 원했습니다.
Application-level sharding required us to make the following design decisions:
애플리케이션-레벨 샤딩을 위해서 다음과 같은 설계 결정을 내려야 했습니다:
- What data should we shard? Part of what makes our data set unique is that the
blocktable reflects trees of user-created content, which can vary wildly in size, depth, and branching factor. A single large enterprise customer, for instance, generates more load than many average personal workspaces combined. We wanted to only shard the necessary tables, while preserving locality for related data. - 어떤 데이터를 샤딩해야하는가? 노션이 다루는 데이터셋을 특별하게 만드는 것은 사용자-생성 컨텐츠 트리를 나타내는
block테이블이였습니다. 이는 크기, 깊이 그리고 분기와 같은 요소에서 넓고 다양해질 수 있습니다. 거대한 단일 기업 고객의 경우, 예를 들자면 다수의 평균적인 개인 워크스페이스의 통합보다 더 많은 부하를 만들어낼 수 있습니다. 노션팀은 관련 있는 데이터들의 지역성을 지키는 동시에 오직 필요한 테이블만 샤딩하기를 원했습니다. - How should we partition the data? Good partition keys ensure that tuples are uniformly distributed across shards. The choice of partition key also depends on application structure, since distributed joins are expensive and transactionality guarantees are typically limited to a single host.
- 어떻게 데이터를 파티셔닝 할 것인가? 좋은 파티션 키는 튜플이 샤드 사이에서 균일하게 분포되는 것이 보장되는 것인데요. 또한 파티션 키의 선택은 애플리케이션 구조에 종속적이며, 분산 조인은 값비싸고 트랜잭션 보장은 일반적으로 단일 호스트에 국한되어 있습니다.
- How many shards should we create? How should those shards be organized? This consideration encompasses both the number of logical shards per table, and the concrete mapping between logical shards and physical hosts.
- 얼마나 많은 샤드를 생성해야할 것인가? 생성된 샤드들은 얼마나 정렬되어 있어야 하는가? 이 결정은 테이블 당 논리적인 샤드의 수와 논리적 샤드와 물리적 호스트간의 구체적인 매핑을 아우르는 것입니다.
Decision 1: Shard all data transitively related to block
결정1: 블록과 연관된 모든 데이터를 샤딩하기
Since Notion’s data model revolves around the concept of a block, each occupying a row in our database, the block table was the highest-priority for sharding. However, a block may reference other tables like space (workspaces) or discussion (page-level and inline discussion threads). In turn, a discussion may reference rows in the comment table, and so on.
노션의 데이터 모델은 블록 개념을 중심으로 하며, 각각은 데이터베이스의 한 행을 차지합니다. block 테이블은 샤딩의 가장 높은 우선 순위였습니다. 그러나 블록은 space(워크스페이스)나 discussion(페이지 레벨 그리고 인라인 논의 스레드)과 같은 다른 테이블을 참조할 가능성도 존재했습니다. 또 한 술 더떠서 discussion은 comment 테이블의 한 행을 참조하는 등 이런 것들이 계속되는 식이였죠.
We decided to shard all tables reachable from the block table via some kind of foreign key relationship. Not all of these tables needed to be sharded, but if a record was stored in the main database while its related block was stored on a different physical shard, we could introduce inconsistencies when writing to different datastores.
무엇이든 외래키 관계 같은 것들을 통해 block과 연관있는 모든 테이블들을 샤딩하기로 결정했습니다. 이 모든 테이블들이 샤딩 될 필요는 없었지만 이런 가정을 해볼 수 있죠. 만약 어떤 레코드가 메인 데이터베이스에 저장이 되었는데, 이와 연관된 블록은 다른 물리적인 샤드에 저장이 되는 경우 서로 다른 데이터스토어에 쓰기를 하는 경우 일관성이 깨지는 상황에 직면할 수 있었어요.
For example, consider a block stored in one database, with related comments in another database. If the block is deleted, the comments should be updated — but since transactionality guarantees only apply within each datastore, the block deletion could succeed while the comment update fails.
예를 들어, 한 데이터베이스에 블록이 저장되고, 관련된 댓글이 다른 데이터베이스에 저장되는 상황을 고려해봅시다. 만약 블록이 삭제된다면 댓글이 업데이트 되어야겠죠. 그러나 트랜잭션 보장은 오직 각 데이터스토어에 한해서만 적용되기 때문에 블록의 삭제는 되었지만 댓글의 업데이트는 실패하는 상황이 생길 수 있는거죠.
Decision 2: Partition block data by workspace ID
결정2: 워크스페이스 ID를 기준으로 블록 데이터 파티셔닝
Once we decided which tables to shard, we had to divide them up. Choosing a good partition scheme depends heavily on the distribution and connectivity of the data; since Notion is a team-based product, our next decision was to partition data by workspace ID.³
테이블을 샤딩하기로 결정하고 나서, 이 것들을 나누어봐야만 했습니다. 좋은 파티셔닝 스킴은 전적으로 데이터의 분산과 연결성에 의존합니다. 노션은 팀 기반의 프로덕트이며 다음 결정은 데이터를 워크스페이스 ID로 파티셔닝하는 것이였습니다.
Each workspace is assigned a UUID upon creation, so we can partition the UUID space into uniform buckets. Because each row in a sharded table is either a block or related to one, and each block belongs to exactly one workspace, we used the workspace ID as the partition key. Since users typically query data within a single workspace at a time, we avoid most cross-shard joins.
각각의 워크스페이스는 생성 시 UUID가 할당되므로, UUID 공간을 균일한 버켓으로 파티셔닝하는 것이 가능했습니다. 샤딩된 테이블의 각 행은 블록이거나 블록과 관련이 있었고, 각 블록은 정확하게 하나의 워크스페이스에 속합니다. 따라서 워크스페이스 ID를 파티션 키로 사용할 수 있었죠. 사용자들은 일반적으로 하나의 워크스페이스 내에서만 데이터를 쿼리하기 때문에 대부분의 경우에서 샤드 간 조인(cross-shard join)을 피할 수 있습니다.
Decision 3: Capacity planning
결정3: 용량 계획

Having decided on a partitioning scheme, our goal was to design a sharded setup that would handle our existing data and scale to meet our two-year usage projection with low effort. Here were some of our constraints:
파티셔닝 스킴을 결정한 후, 노션팀의 목표는 기존의 데이터와 향후 2년간의 예측치에 대해 스케일링을 적은 노력으로 다루는 샤딩 세팅을 설계하는 것이였습니다. 다음은 고려한 일부 제약 사항입니다:
- Instance type: Disk I/O throughput, quantified in IOPS, is limited by both AWS instance type as well as disk volume. We needed at least 60K total IOPS to meet existing demand, with the capacity to scale further if needed.
- 인스턴스 타입: IOPS로 계측되는 디스크 I/O 처리량은 AWS 인스턴스 타입과 디스크 볼륨에 의해 제한됩니다. 노션팀은 기존 요구 사항을 다루기 위한 최소한 60K의 총 IOPS가 필요했으며, 필요에 따라 용량을 더 확장 가능해야 했습니다.
- Number of physical and logical shards: To keep Postgres humming and preserve RDS replication guarantees, we set an upper bound of 500 GB per table and 10 TB per physical database. We needed to choose a number of logical shards and a number of physical databases, such that the shards could be evenly divided across databases.
- 물리적/논리적 샤드의 수: Postgres를 원활하게 유지하고 RDS의 복제 보장을 보존하기 위해, 테이블당 500GB의 상한과 물리 데이터베이스 당 10TB의 상한을 세팅했습니다. 논리적 샤드의 수와 물리적 데이터베이스의 수를 선택해야했는데, 이 때 샤드가 데이터베이스 전체에 균등하게 분할될 수 있도록 해야했습니다.
- Number of instances: More instances means higher maintenance cost, but a more robust system.
- 인스턴스의 수: 더 많은 인스턴스의 수는 더 높은 관리 비용을 의미하지만, 이는 또한 견고한 시스템을 의미하기도 합니다.
- Cost: We wanted our bill to scale linearly with our database setup, and we wanted the flexibility to scale compute and disk space separately.
- 비용: 데이터베이스 설정에 따라 선형적으로 요금이 증가하며 컴퓨팅과 디스크 공간을 별도로 확장할 수 있는 유연성을 필요로 했습니다.
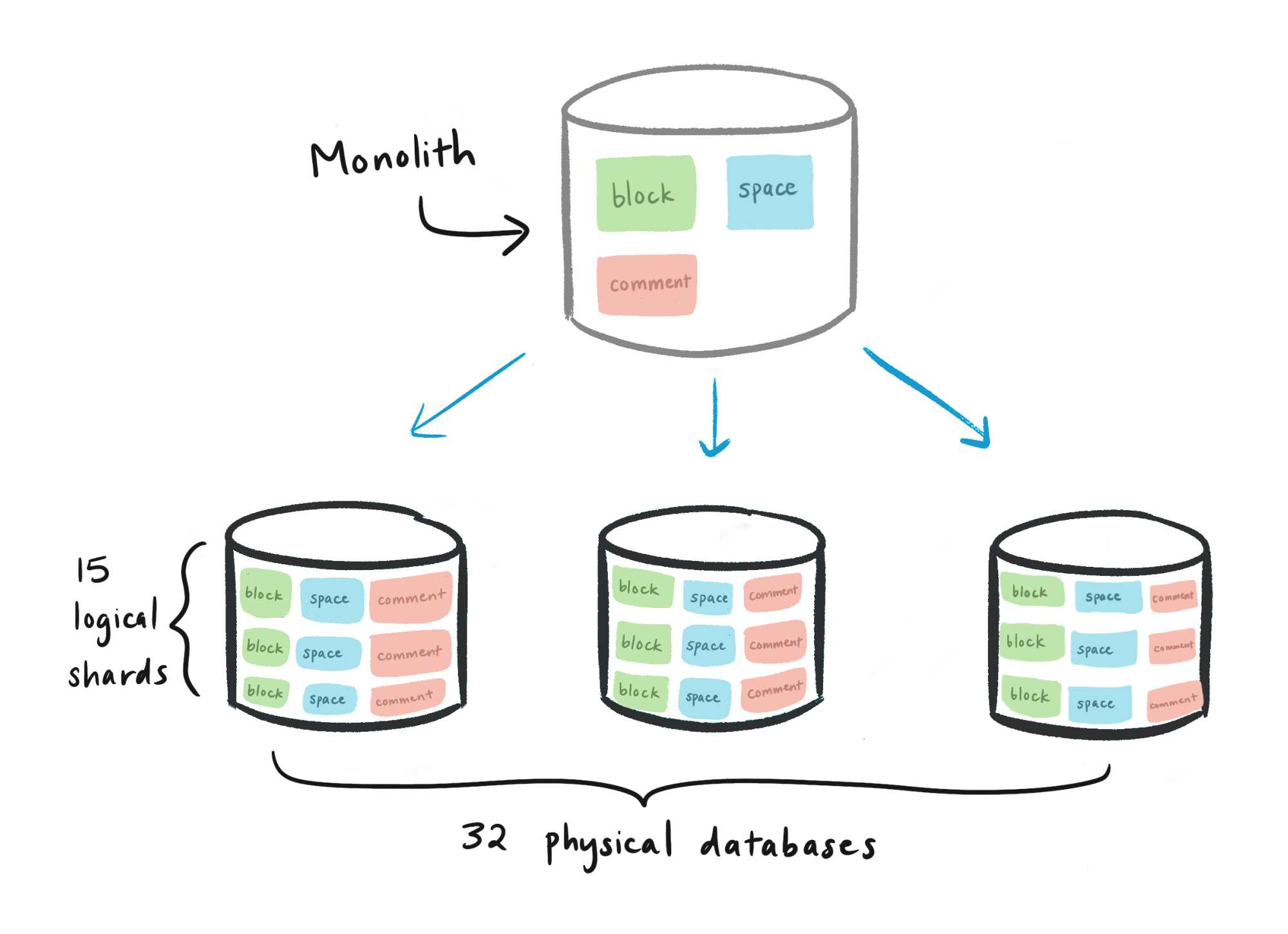
After crunching the numbers, we settled on an architecture consisting of 480 logical shards evenly distributed across 32 physical databases. The hierarchy looked like this:
숫자를 계산해본 결과, 32개의 물리적 데이터베이스에 걸쳐 균등하게 분산되어있는 480개의 논리적 샤드로 구성된 아키텍처를 결정했습니다. 계층 구조는 다음과 같습니다:
- 물리적 데이터베이스 (총 32개)
- Postgres 스키마를 나타내는 논리적 샤드 (데이터베이스 당 15개, 총 480개)
block테이블 (논리적 샤드 당 1, 총 480개)collection테이블 (논리적 샤드 당 1, 총 480개)space테이블 (논리적 샤드 당 1, 총 480개)- etc. 모든 샤딩된 테이블을 위한 것
- Postgres 스키마를 나타내는 논리적 샤드 (데이터베이스 당 15개, 총 480개)
You may be wondering, "Why 480 shards? I thought all computer science was done in powers of 2, and that's not a drive size I recognize!"
아마도 궁금해하실 수도 있는데요. 왜 480개임? 컴퓨터 사이언스의 모든 것은 2의 제곱으로 끝나는 줄 알았는데? 또 내가 알고 있던 드라이브 사이즈도 아니고 말야!There were many factors that led to the choice of 480:
480을 선택하게 된 요소는 아주 많아요.
- 2
- 3
- 4
- 5
- 6
- 8
- 10, 12, 15, 16, 20, 24, 30, 32, 40, 48, 60, 80, 96, 120, 160, 240
The point is, 480 is divisible by a lot of numbers — which provides flexibility to add or remove physical hosts while preserving uniform shard distribution. For example, in the future we could scale from 32 to 40 to 48 hosts, making incremental jumps each time.
핵심은 480이 아주 많은 숫자들로 나눌 수 있다는 것이에요. 이는 샤드의 균일한 분포를 유지하면서 물리적 호스트를 더하거나 뺄 수 있는 유연함을 제공합니다. 예를들어 미래에 32에서 40으로, 40에서 48로 호스트를 확장할 수도 있는데 매번 점진적인 증가를 할 수 있습니다.
By contrast, suppose we had 512 logical shards. The factors of 512 are all powers of 2, meaning we’d jump from 32 to 64 hosts if we wanted to keep the shards even. Any power of 2 would require us to double the number of physical hosts to upscale. Pick values with a lot of factors!
반면에, 512개의 논리적 샤드를 가지고 있다고 가정해봅시다. 512의 인수는 모두 2의 거듭제곱인데요. 샤드를 균일하게 유지하고 싶다면 32에서 64로 뛰어야 한다는 것을 의미해요. 2의 제곱인 어떠한 값이든 물리적 호스트를 업스케일 하기 위해서는 두 배로 늘려야 하는거죠. 인수가 아주 많은 값을 고르세요!
We chose to construct schema001.block, schema002.block, etc. as separate tables, rather than maintaining a single partitioned block table per database with 15 child tables. Natively partitioned tables introduce another piece of routing logic:
- Application code: workspace ID → physical database.
- Partition table: workspace ID → logical schema.
schema001.block, schema002.block 등을 별도의 테이블로 분리해서 구성하기로 결정했습니다. 각 데이터베이스 당 15개의 하위 테이블을 가진 단일 파티션된 block x테이블을 유지하는 대신에요. 원천적으로 분할된 테이블은 몇 가지 라우팅 로직의 도입으로 이어집니다.
- 애플리케이션 코드: 워크스페이스 ID → 물리적 데이터베이스
- 파티션된 테이블: 워크스페이스 ID → 논리적 스키마
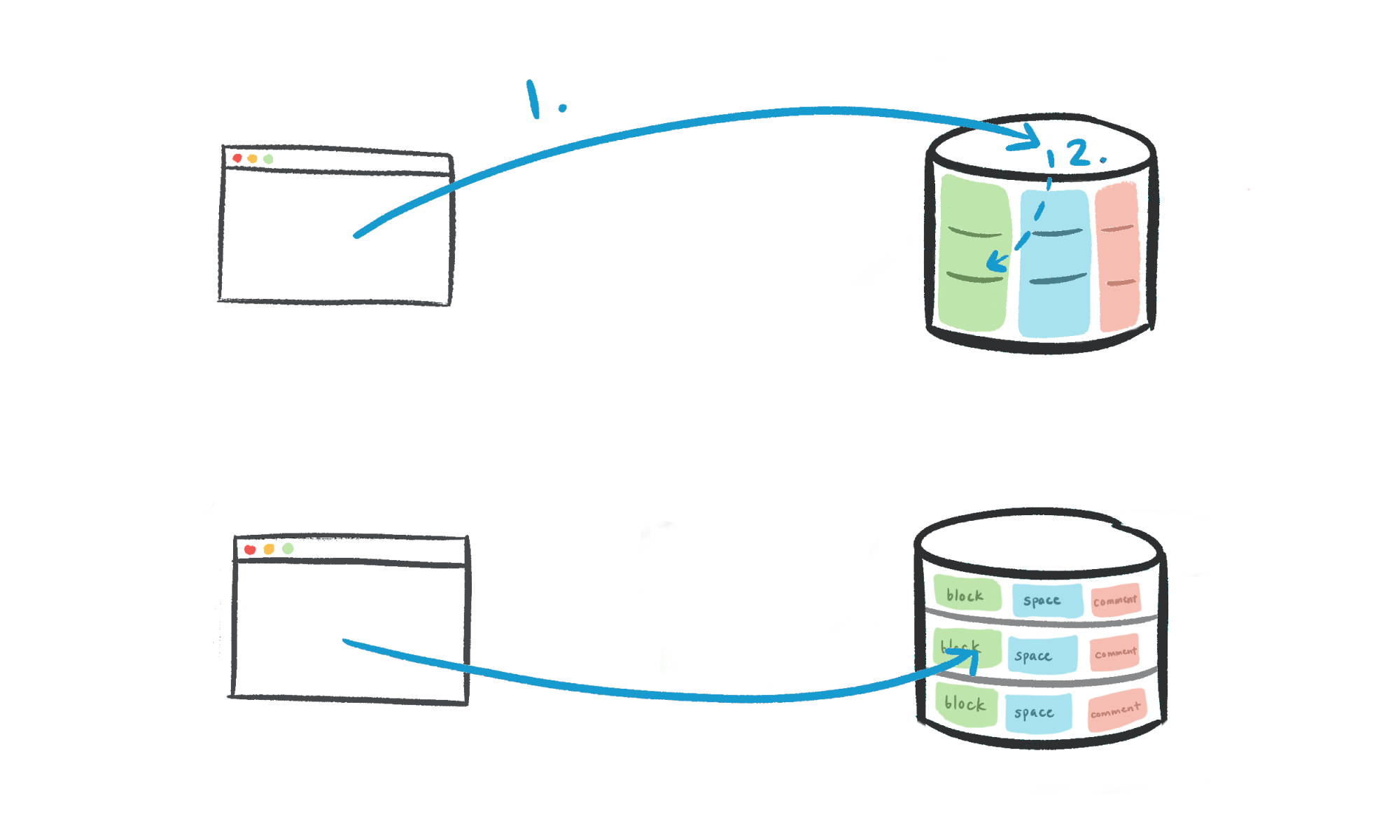
워크스페이스 ID로 논리적 샤딩으로 라우팅하는 것에 대한 SSOT(단일 진실 공급원)를 원했습니다. 따라서 테이블을 분리하는 구성을 하였고, 모든 라우팅에 대한 것은 애플리케이션이 수행하는 것을 택하였습니다.
Migrating to shards
샤드로 마이그레이션
Once we established our sharding scheme, it was time to implement it. For any migration, our general framework goes something like this:
- Double-write: Incoming writes get applied to both the old and new databases.
- Backfill: Once double-writing has begun, migrate the old data to the new database.
- Verification: Ensure the integrity of data in the new database.
- Switch-over: Actually switch to the new database. This can be done incrementally, e.g. double-reads, then migrate all reads.
샤딩 스킴이 결정되고 난 후에는 구현만 남게되었습니다. 마이그레이션에 대한 노션의 일반적인 프레임워크는 다음과 같이 가져가기로 했습니다:
- 더블 라이트: 들어오는 쓰기 작업은 기존과 신규 데이터베이스 모두에 적용한다.
- 백필: 더블-라이팅이 시작되고 나면 기존 데이터를 신규 데이터베이스로 마이그레이션 한다.
- 검증: 신규 데이터베이스에 있는 데이터의 정합성을 검사한다.
- 스위치 오버: 실제로 새 데이터베이스로 전환합니다. 이 작업은 점진적으로 수행될 수 있으며, 예를 들어 더블 리드 후 모든 리드를 마이그레이션 하는 식입니다.
Double-writing with an audit log
audit 로그로 더블 라이팅
The double-write phase ensures that new data populates both the old and new databases, even if the new database isn’t yet being used. There are several options for double-writing:
- Write directly to both databases: Seemingly straightforward, but any issue with either write can quickly lead to inconsistencies between databases, making this approach too flaky for critical-path production datastores.
- Logical replication: Built-in Postgres functionality that uses a publish/subscribe model to broadcast commands to multiple databases. Limited ability to modify data between source and target databases.
- Audit log and catch-up script: Create an audit log table to keep track of all writes to the tables under migration. A catch-up process iterates through the audit log and applies each update to the new databases, making any modifications as needed.
더블-라이트 단계는 새 데이터가 기존 데이터베이스와 신규 데이터베이스 양쪽에서 생성되는 것을 보장합니다. 새 데이터베이스가 아직 사용되지 않더라도 말이죠. 더블 라이팅에는 몇 가지 옵션이 존재해요:
- 양쪽 데이터베이스에 직접 쓰기: 겉으로는 간단해보이지만, 쓰기 작업이 데이터베이스 간 불일치로 이어질 수 있으며, critical-path 프로덕션 데이터 스토어에 대해서는 너무 불안정한 접근 방식이 될 수 있습니다.
- 논리적 복제: 내장된 Postgres 기능으로, pub/sub 모델을 이용해 여러 데이터베이스에 명령을 브로드캐스트 할 수 있습니다. 원본과 대상 데이터베이스 사이의 데이터 수정에 대해 제한적입니다.
- audit 로그와 catch-up 스크립트: audit 로그 테이블을 생성해 마이그레이션 대상인 테에블에 대한 모든 쓰기를 추적합니다. catch-up 프로세스는 audit 로그를 통해 새 데이터베이스에 각각의 업데이트를 적용할 수 있고 수정도 필요하다면 할 수 있습니다.
We chose the audit log strategy over logical replication, since the latter struggled to keep up with block table write volume during the initial snapshot step.
논리적 복제 대신 audit log 전략을 택했습니다. 논리적 복제는 초기 스냅샷 단계에서 block 테이블의 쓰기 볼륨을 따라 잡는 것이 고통스러웠기 때문입니다.
We also prepared and tested a reverse audit log and script in case we needed to switch back from shards to the monolith. This script would capture any incoming writes to the sharded database, and allow us to replay those edits on the monolith. In the end, we didn't need to revert, but it was an important piece of our contingency plan.
노션팀은 샤딩에서 모놀리스로 롤백하는 상황에 대해 대비하여 역방향 감사 로그(reverse audit log)와 그에 대한 스크립트를 준비하고 테스트 했습니다. 이 스크립트는 샤딩된 데이터베이스로 들어오는 어떠한 쓰기든 캡쳐하고, 이러한 수정 사항들을 모놀리스에서 replay할 수 있도록 해두었습니다. 결국 리버트를 할 필요는 없게 되었지만 만약을 대비하는 계획의 중요한 부분 중 하나였죠.
과거 데이터 백필
Once incoming writes were successfully propagating to the new databases, we initiated a backfill process to migrate all existing data. With all 96 CPUs (!) on the m5.24xlarge instance we provisioned, our final script took around three days to backfill the production environment.
들어오는 쓰기를 성공적으로 새 데이터베이스에 전파하였고, 모든 기존 데이터를 마이그레이션하는 백필 프로세스에 착수하였습니다. 프로비저닝해둔 m5.24xlarge 인스턴스의 96개의 CPU로 최종 스크립트를 이용해 프로덕션 환경에 백필하는데 3일 정도가 소요되었습니다.
Any backfill worth its salt should compare record versions before writing old data, skipping records with more recent updates. By running the catch-up script and backfill in any order, the new databases would eventually converge to replicate the monolith.
어떠한 백필이라도 가치가 있는 경우, 구 데이터를 쓰기 전에 레코드 버전들과 비교해서 최근에 업데이트가 있는 레코드는 건너뜁니다. catch-up 스크립트와 backfill을 어떤 순서로든 실행하면, 새 데이터베이스는 결국 모놀리스를 복제하도록 수렴하게 됩니다.
데이터 정합성 검증
Migrations are only as good as the integrity of the underlying data, so after the shards were up-to-date with the monolith, we began the process of verifying correctness.
- Verification script: Our script verified a contiguous range of the UUID space starting from a given value, comparing each record on the monolith to the corresponding sharded record. Because a full table scan would be prohibitively expensive, we randomly sampled UUIDs and verified their adjacent ranges.
- “Dark” reads: Before migrating read queries, we added a flag to fetch data from both the old and new databases (known as dark reading). We compared these records and discarded the sharded copy, logging discrepancies in the process. Introducing dark reads increased API latency, but provided confidence that the switch-over would be seamless.
As a precaution, the migration and verification logic were implemented by different people. Otherwise, there was a greater chance of someone making the same error in both stages, weakening the premise of verification.
마이그레이션은 마이그레이션 된 데이터가 검증되었을 때만 유효합니다. 따라서 샤드들이 모놀리스를 따라잡고 난 후, 정합성 검증 프로세스를 시작했습니다.
- 검증 스크립트: 검증 스크립트는 주어진 값부터 시작하여 UUID 공간의 인접한 범위를 검증합니다. 모놀리스에 대한 각각의 레코드와 이에 해당되는 샤딩된 레코드를 비교합니다. 풀 테이블 스캔은 엄청나게 비싸기 때문에 랜덤하게 UUID를 샘플링하여 인접한 친구들을 검증했습니다.
- 다크 리드: 리드 쿼리를 마이그레이션 하기에 앞서, 기존과 신규 데이터베이스 양쪽에서 데이터를 fetch(다크 리딩이라 부름)하는 플래그를 추가했습니다. 이 레코드들을 비교하고 샤딩된 카피를 폐기했고, 이 과정에서 불일치를 로깅했습니다. 다크 리딩은 API 레이턴시 증가로 이어지긴 했지만 심리스하게 스위치 오버하는 자신감을 가지게 해주었습니다.
예방 차원에서 마이그레이션과 검증 로직은 서로 다른 사람들이 작성하였습니다. 그렇지 않으면 각각의 단계에서 동일한 에러를 저지를 가능성이 더 컸기 때문이며, 이는 검증의 전제가 약화되는 것을 의미합니다.
Difficult lessons learned
배우게 된 어려운 교훈들
While much of the sharding project captured Notion’s engineering team at its best, there were many decisions we would reconsider in hindsight. Here are a few examples:
샤딩 프로젝트의 많은 부분이 노션 엔지니어링 팀이 최선을 다한 결과로 채워지긴 했지만, 뒤늦게 깨닫게 된 재고할 필요가 있는 결정들이 많았습니다. 다음은 몇 가지 예시입니다:
- Shard earlier. As a small team, we were keenly aware of the tradeoffs associated with premature optimization. However, we waited until our existing database was heavily strained, which meant we had to be very frugal with migrations lest we add even more load. This limitation kept us from using logical replication to double-write. The workspace ID —our partition key— was not yet populated in the old database, and backfilling this column would have exacerbated the load on our monolith. Instead, we backfilled each row on-the-fly when writing to the shards, requiring a custom catch-up script.
- 샤딩 일찍할걸. 소규모 팀으로서, 섣부른 최적화에 관련된 트레이드 오프를 잘 알고 있었습니다. 그러나 기존 데이터베이스가 부하를 빡세게 받을 때까지 기다렸고, 이는 마이그레이션을 매우 간소화하여 진행할 수 밖에 없게 만들었고 더 많은 부하를 받지 않도록 노력해야 했습니다. 이 제약으로 인해 논리적 복제를 이용한 더블라이트를 할 수 없었습니다. 파티션 키인 workspace ID는 이전 데이터베이스에서는 생성되지 않았기 때문에 모놀리스에 이 컬럼을 백필링하는 것은 부하를 유발할 수 있었습니다. 대신에 샤드에 쓰기를 할 때 각 행에 대해 백필링 하도록 해야해서 커스텀 catch-up 스크립트가 필요해졌습니다.
- Aim for a zero-downtime migration. Double-write throughput was the primary bottleneck in our final switch-over: once we took the server down, we needed to let the catch-up script finish propagating writes to the shards. Had we spent another week optimizing the script to spend <30 seconds catching up the shards during the switch-over, it may have been possible to hot-swap at the load balancer level without downtime.
- 제로 다운 타임 마이그레이션을 목표로 할 걸. 더블 라이트의 처리량이 최종 스위치 오버에서 주요한 병목으로 작용했습니다. 서버가 종료되고 나면 catch-up 스크립트가 샤드로 쓰기 작업을 전파하는 것을 완료해야했습니다. 한 주 정도 써서 스크립트를 최적화하여 30초 미만으로 catch-up 스크립트가 샤딩하도록 했다면 아마도 다운타임 없이 로드 밸런서 레벨에서 핫스왑 가능했을지도 몰라요.
- Introduce a combined primary key instead of a separate partition key. Today, rows in sharded tables use a composite key:
id, the primary key in the old database; andspace_id, the partition key in the current arrangement. Since we had to do a full table scan anyway, we could’ve combined both keys into a single new column, eliminating the need to passspace_idsthroughout the application. - 별도의 파티션 키 대신 복합 PK를 도입할걸. 현재 샤딩된 테이블의 행은 복합키(기존 데이터베이스의 PK인 id, 현재 구성의 파티션 키인 space_id)를 사용합니다. 어찌됐든 풀 테이블 스캔을 해야만 했기 때문에, 두 키를 하나의 새로운 컬럼으로 합칠 수도 있었습니다. 그러면 애플리케이션 전체에 걸쳐
space_ids를 전달하는 일을 없앴을텐데 말이에요.
Despite these what-ifs, sharding was a tremendous success. For Notion users, a few minutes of downtime made the product tangibly faster. Internally, we demonstrated coordinated teamwork and decisive execution given a time-sensitive goal.
이러한 만약들에도 불구하고, 샤딩은 엄청난 성공이었습니다. 노션 사용자에게 있어 다운타임 몇 분은 프로덕트가 명백히 빨라지게 만들었습니다. 내부적으로는 일분일초가 중요한 목표가 주어졌을 때 조직적인 팀워크와 결단력있는 실행을 보여주었습니다.
If urgent timelines don’t stop you from thinking rigorously about long-term technical implications, we’d love to chat — join us!
긴급한 일정 속에서도 장기적인 기술적 영향도에 대해서 엄격하게 생각하실 수 있는 분이라면, 이야기 하고 싶어요 - 함께 해주세요!